MySQL之全库备份与恢复--innobackupex
本文共 3219 字,大约阅读时间需要 10 分钟。
结合相关脚本使用,效果更佳~MySQL脚本(percona-tools)http://blog.itpub.net/29510932/viewspace-1787716/ -------------------------------------------------------------------------------------------------正文---------------------------------------------------------------------------------------------------------------工具:percona-xtrabackup-2.3.2环境:Linux 2.6.32-279.el6.x86_64数据库版本:源数据库与目标数据库版本一致Server version: 5.6.26-log MySQL Community Server (GPL)----------------------------------------------------------------------------------------------工具的安装------------------------------------------------------------------------------------------------------------ 1.percona官网下载percona-xtrabackup-2.3.2 https://www.percona.com/downloads/XtraBackup/LATEST/注意系统的类型,内核版本,和32/64位的区别 2.服务器环境的搭建 新版本的工具对系统环境的要求比旧版本多了点,执行以下语句 yum install libaio libaio-devel perl-Time-HiRes curl curl-devel zlib-devel openssl-devel perl cpio expat-devel gettext-devel perl-ExtUtils-MakeMaker perl-DBD-MySQL.* package -y 同时还需要如下两个包libev-4.04-2.el6.x86_64.rpm,zlib-1.2.3-29.el6.x86_64.rpm,这两个包可以在rpmfind里面搜索到如果用到了压缩,需要qpress,官网http://www.quicklz.com/ 下载位置如下,解压缩出来就是一个qpress的文件,复制到/usr/bin/下面即可
2.服务器环境的搭建 新版本的工具对系统环境的要求比旧版本多了点,执行以下语句 yum install libaio libaio-devel perl-Time-HiRes curl curl-devel zlib-devel openssl-devel perl cpio expat-devel gettext-devel perl-ExtUtils-MakeMaker perl-DBD-MySQL.* package -y 同时还需要如下两个包libev-4.04-2.el6.x86_64.rpm,zlib-1.2.3-29.el6.x86_64.rpm,这两个包可以在rpmfind里面搜索到如果用到了压缩,需要qpress,官网http://www.quicklz.com/ 下载位置如下,解压缩出来就是一个qpress的文件,复制到/usr/bin/下面即可 -----------------------------------------------------------------------------------------------备份恢复演练-------------------------------------------------------------------------------------------------------- 全量备份使用的命令: innobackupex --user=root --passwordPWD --parallel=8 --no-timestamp --use-memory=8G /data/2015-11-02 附带参数意义:parallel -->并行度,同时使用8个线程进行备份操作no-timestamp -->不使用时间戳,直接在指定的目录下生成备份文件,如果不加这个参数,那么会在备份文件下根据当前时间单独建立一个文件名为具体时间的目录来存放备份文件use-memory -->使用的内存数量,在不影响服务器上其他应用的前提下,可以稍微调高一些,主要用于apply-log阶段的crash recovery,其他阶段加与不加没什么影响 摘抄部分比较有用的参数说明: rsync -->开启本地文件传输的插件,用于非InnoDB引擎的文件拷贝(否则用cp),在处理很多的DB或者表的数据库实例时会更快databases -->指定备份的数据库,多个数据库之间用空格分开,备份表就写成database1.table1 如果一切没有问题,那么在最后会有如下输出,可以看到还是有锁表的,虽然备份的速度比较快,还是要注意一下对业务的影响;
-----------------------------------------------------------------------------------------------备份恢复演练-------------------------------------------------------------------------------------------------------- 全量备份使用的命令: innobackupex --user=root --passwordPWD --parallel=8 --no-timestamp --use-memory=8G /data/2015-11-02 附带参数意义:parallel -->并行度,同时使用8个线程进行备份操作no-timestamp -->不使用时间戳,直接在指定的目录下生成备份文件,如果不加这个参数,那么会在备份文件下根据当前时间单独建立一个文件名为具体时间的目录来存放备份文件use-memory -->使用的内存数量,在不影响服务器上其他应用的前提下,可以稍微调高一些,主要用于apply-log阶段的crash recovery,其他阶段加与不加没什么影响 摘抄部分比较有用的参数说明: rsync -->开启本地文件传输的插件,用于非InnoDB引擎的文件拷贝(否则用cp),在处理很多的DB或者表的数据库实例时会更快databases -->指定备份的数据库,多个数据库之间用空格分开,备份表就写成database1.table1 如果一切没有问题,那么在最后会有如下输出,可以看到还是有锁表的,虽然备份的速度比较快,还是要注意一下对业务的影响;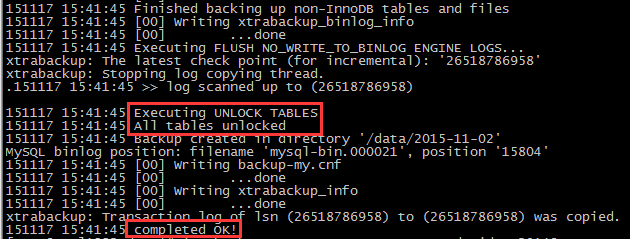 scp拷贝到目标库以后,先用apply-log对备份文件进行预处理 innobackupex --apply-log /data/2015-11-02/ 处理结果如下图
scp拷贝到目标库以后,先用apply-log对备份文件进行预处理 innobackupex --apply-log /data/2015-11-02/ 处理结果如下图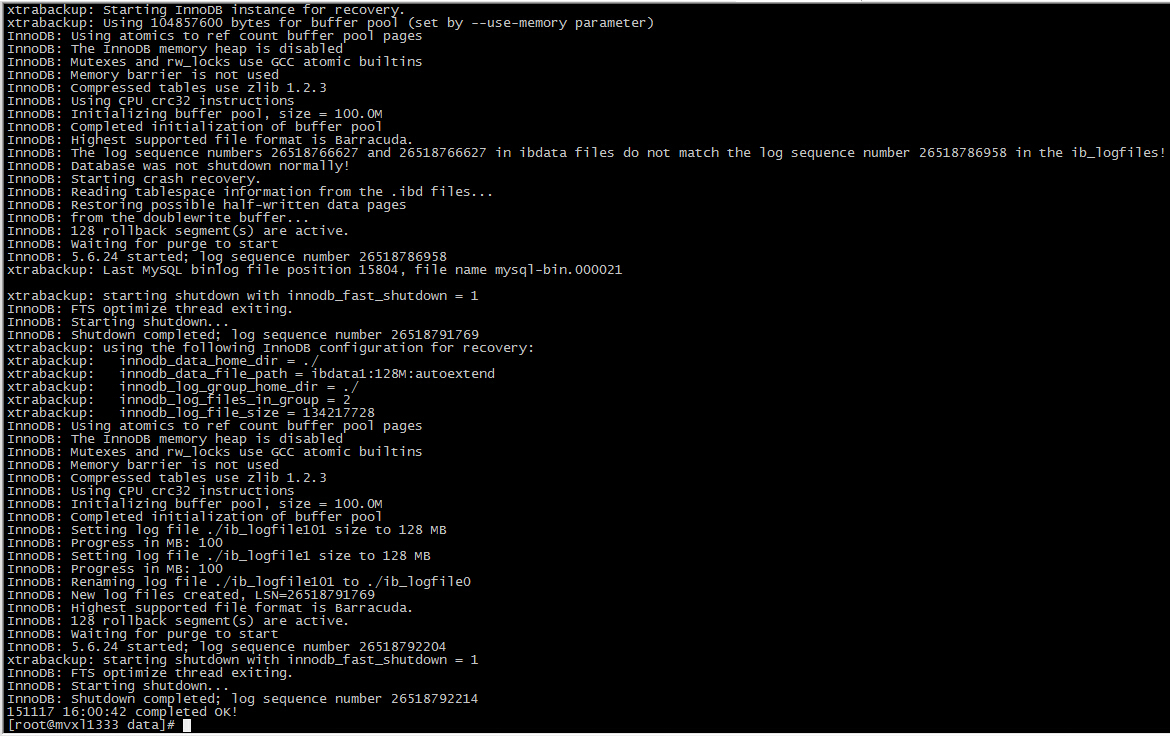 在这个阶段出问题的话,大部分时候是目标库和源库的数据库设置有问题,统一一下两个库的my.cnf预处理完成以后,就可以把数据文件拷贝回去了,使用copy-back innobackupex --copy-back /data/2015-11-02/ 一切ok的话,最后会有如下输出
在这个阶段出问题的话,大部分时候是目标库和源库的数据库设置有问题,统一一下两个库的my.cnf预处理完成以后,就可以把数据文件拷贝回去了,使用copy-back innobackupex --copy-back /data/2015-11-02/ 一切ok的话,最后会有如下输出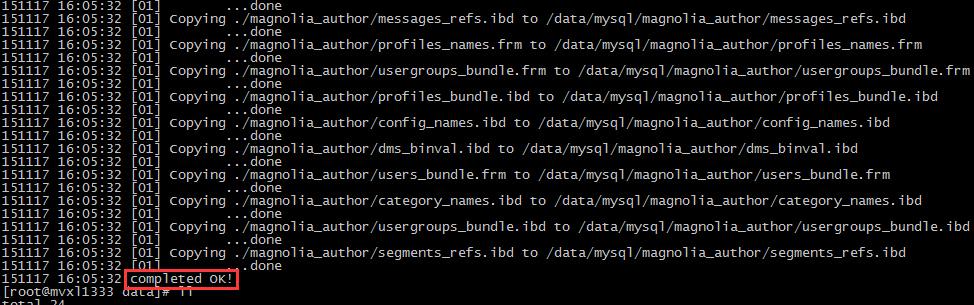 在这个阶段容易出问题的地方: 1.源数据库和目标数据库的my.cnf配置不同2.datadir指定的路径,存在目录,或者目录下存在文件,(可以使用参数去强制进行覆盖,但是不推荐,有风险) 3.之前apply-log失败了 4.找不到my.cnf 如果直到copy-back都没有出问题的话,那么一般就算是正常恢复了,先修改文件夹权限(chown -R mysql:mysq: mysql),然后启动mysql
在这个阶段容易出问题的地方: 1.源数据库和目标数据库的my.cnf配置不同2.datadir指定的路径,存在目录,或者目录下存在文件,(可以使用参数去强制进行覆盖,但是不推荐,有风险) 3.之前apply-log失败了 4.找不到my.cnf 如果直到copy-back都没有出问题的话,那么一般就算是正常恢复了,先修改文件夹权限(chown -R mysql:mysq: mysql),然后启动mysql 大功告成~-----------------------------------------------------------------------------------------------额外的内容--------------------------------------------------------------------------------------------------------如果备份的库,数据库规模比较大,可以开启压缩,在全量备份的时候加入--compress --compress-threads=8即可值得注意的是,如果使用了压缩,那么在目标库进行预处理之前,先要用innobackupex --decompress /data/2015-11-02/指令把文件解压缩,然后再依次进行预处理和以后的步骤 压缩的效果可以对比一下,从上至下依次为原始数据库文件,普通全量备份,压缩全量备份(请无视中间的那个16k的文件夹..._(:з」∠)_...)
大功告成~-----------------------------------------------------------------------------------------------额外的内容--------------------------------------------------------------------------------------------------------如果备份的库,数据库规模比较大,可以开启压缩,在全量备份的时候加入--compress --compress-threads=8即可值得注意的是,如果使用了压缩,那么在目标库进行预处理之前,先要用innobackupex --decompress /data/2015-11-02/指令把文件解压缩,然后再依次进行预处理和以后的步骤 压缩的效果可以对比一下,从上至下依次为原始数据库文件,普通全量备份,压缩全量备份(请无视中间的那个16k的文件夹..._(:з」∠)_...) 同样的,也可以使用这种备份恢复的方式来进行数据库升级,采用同一个源目标库,使用MySQL-5.7.9-GA作为目标库时,使用一样的步骤进行数据文件的恢复,在启动MySQL以后,先执行mysql_update -uroot -p命令对系统表进行更新
同样的,也可以使用这种备份恢复的方式来进行数据库升级,采用同一个源目标库,使用MySQL-5.7.9-GA作为目标库时,使用一样的步骤进行数据文件的恢复,在启动MySQL以后,先执行mysql_update -uroot -p命令对系统表进行更新 关于innobackupex的其他备份恢复功能,抽空再更新...... 看官方文档写的是可以从全库备份的备份文件里面恢复单表数据,但是只能够在percona server的XtraDB上面使用 原文:|Percona XtraBackup| based backups also allow for table level recovery even though the backup was done at the database level (needs the recovery database server to be |Percona Server| with XtraDB). index_merge和metadata lock继续拖.....
关于innobackupex的其他备份恢复功能,抽空再更新...... 看官方文档写的是可以从全库备份的备份文件里面恢复单表数据,但是只能够在percona server的XtraDB上面使用 原文:|Percona XtraBackup| based backups also allow for table level recovery even though the backup was done at the database level (needs the recovery database server to be |Percona Server| with XtraDB). index_merge和metadata lock继续拖.....
2.服务器环境的搭建 新版本的工具对系统环境的要求比旧版本多了点,执行以下语句 yum install libaio libaio-devel perl-Time-HiRes curl curl-devel zlib-devel openssl-devel perl cpio expat-devel gettext-devel perl-ExtUtils-MakeMaker perl-DBD-MySQL.* package -y 同时还需要如下两个包libev-4.04-2.el6.x86_64.rpm,zlib-1.2.3-29.el6.x86_64.rpm,这两个包可以在rpmfind里面搜索到如果用到了压缩,需要qpress,官网http://www.quicklz.com/ 下载位置如下,解压缩出来就是一个qpress的文件,复制到/usr/bin/下面即可-----------------------------------------------------------------------------------------------备份恢复演练-------------------------------------------------------------------------------------------------------- 全量备份使用的命令: innobackupex --user=root --passwordPWD --parallel=8 --no-timestamp --use-memory=8G /data/2015-11-02 附带参数意义:parallel -->并行度,同时使用8个线程进行备份操作no-timestamp -->不使用时间戳,直接在指定的目录下生成备份文件,如果不加这个参数,那么会在备份文件下根据当前时间单独建立一个文件名为具体时间的目录来存放备份文件use-memory -->使用的内存数量,在不影响服务器上其他应用的前提下,可以稍微调高一些,主要用于apply-log阶段的crash recovery,其他阶段加与不加没什么影响 摘抄部分比较有用的参数说明: rsync -->开启本地文件传输的插件,用于非InnoDB引擎的文件拷贝(否则用cp),在处理很多的DB或者表的数据库实例时会更快databases -->指定备份的数据库,多个数据库之间用空格分开,备份表就写成database1.table1 如果一切没有问题,那么在最后会有如下输出,可以看到还是有锁表的,虽然备份的速度比较快,还是要注意一下对业务的影响; scp拷贝到目标库以后,先用apply-log对备份文件进行预处理 innobackupex --apply-log /data/2015-11-02/ 处理结果如下图 在这个阶段出问题的话,大部分时候是目标库和源库的数据库设置有问题,统一一下两个库的my.cnf预处理完成以后,就可以把数据文件拷贝回去了,使用copy-back innobackupex --copy-back /data/2015-11-02/ 一切ok的话,最后会有如下输出 在这个阶段容易出问题的地方: 1.源数据库和目标数据库的my.cnf配置不同2.datadir指定的路径,存在目录,或者目录下存在文件,(可以使用参数去强制进行覆盖,但是不推荐,有风险) 3.之前apply-log失败了 4.找不到my.cnf 如果直到copy-back都没有出问题的话,那么一般就算是正常恢复了,先修改文件夹权限(chown -R mysql:mysq: mysql),然后启动mysql 大功告成~-----------------------------------------------------------------------------------------------额外的内容--------------------------------------------------------------------------------------------------------如果备份的库,数据库规模比较大,可以开启压缩,在全量备份的时候加入--compress --compress-threads=8即可值得注意的是,如果使用了压缩,那么在目标库进行预处理之前,先要用innobackupex --decompress /data/2015-11-02/指令把文件解压缩,然后再依次进行预处理和以后的步骤 压缩的效果可以对比一下,从上至下依次为原始数据库文件,普通全量备份,压缩全量备份(请无视中间的那个16k的文件夹..._(:з」∠)_...)同样的,也可以使用这种备份恢复的方式来进行数据库升级,采用同一个源目标库,使用MySQL-5.7.9-GA作为目标库时,使用一样的步骤进行数据文件的恢复,在启动MySQL以后,先执行mysql_update -uroot -p命令对系统表进行更新关于innobackupex的其他备份恢复功能,抽空再更新...... 看官方文档写的是可以从全库备份的备份文件里面恢复单表数据,但是只能够在percona server的XtraDB上面使用 原文:|Percona XtraBackup| based backups also allow for table level recovery even though the backup was done at the database level (needs the recovery database server to be |Percona Server| with XtraDB). index_merge和metadata lock继续拖..... 转载地址:http://cfeym.baihongyu.com/
你可能感兴趣的文章
Xamarin截取/删除emoji表情bug解决方案
查看>>
如何将 iOS 工程打包速度提升十倍以上
查看>>
0.0《深入理解计算机系统》笔记(一)栈【插图】
查看>>
【Python】Python中子类怎样调用父类方法
查看>>
python判断list中是否包含某个元素
查看>>
Java操作ini文件 ,解决properties文件中无法读取换行及空格
查看>>
oracle之 Oracle LOB 详解
查看>>
python-下载百度图片到本地
查看>>
ubuntu 安装dlib 出现dlib.so: undefined symbol: png_set_longjmp_fn
查看>>
web开发经验
查看>>
Android 使用DDMS查看内存使用情况
查看>>
大数据等最核心的关键技术:32个算法
查看>>
玩转Bootstrap(JS插件篇)-第1章 模态弹出框 :1-1导入JavaScript插件
查看>>
Vue.js系列之三模板语法
查看>>
libaio.so.1: cannot open shared object file
查看>>
.NET使用存储过程实现对数据库的增删改查
查看>>
微内核与面向组件
查看>>
关于多线程的参数问题
查看>>
Android layer-list的属性和使用具体解释
查看>>
若要允许 GET 请求,请将 JsonRequestBehavior 设置为 AllowGet
查看>>